Code Mode 完整指南:從 Cloudflare 開創到本地開發全場景實踐
最後更新:2026-02-21 涵蓋 Code Mode 原理、平台設定、八大實戰場景與開源伺服器選型。
目錄
一、什麼是 Code Mode?
1.1 Cloudflare 2025/9 提出的 MCP 新範式:典範轉移背景
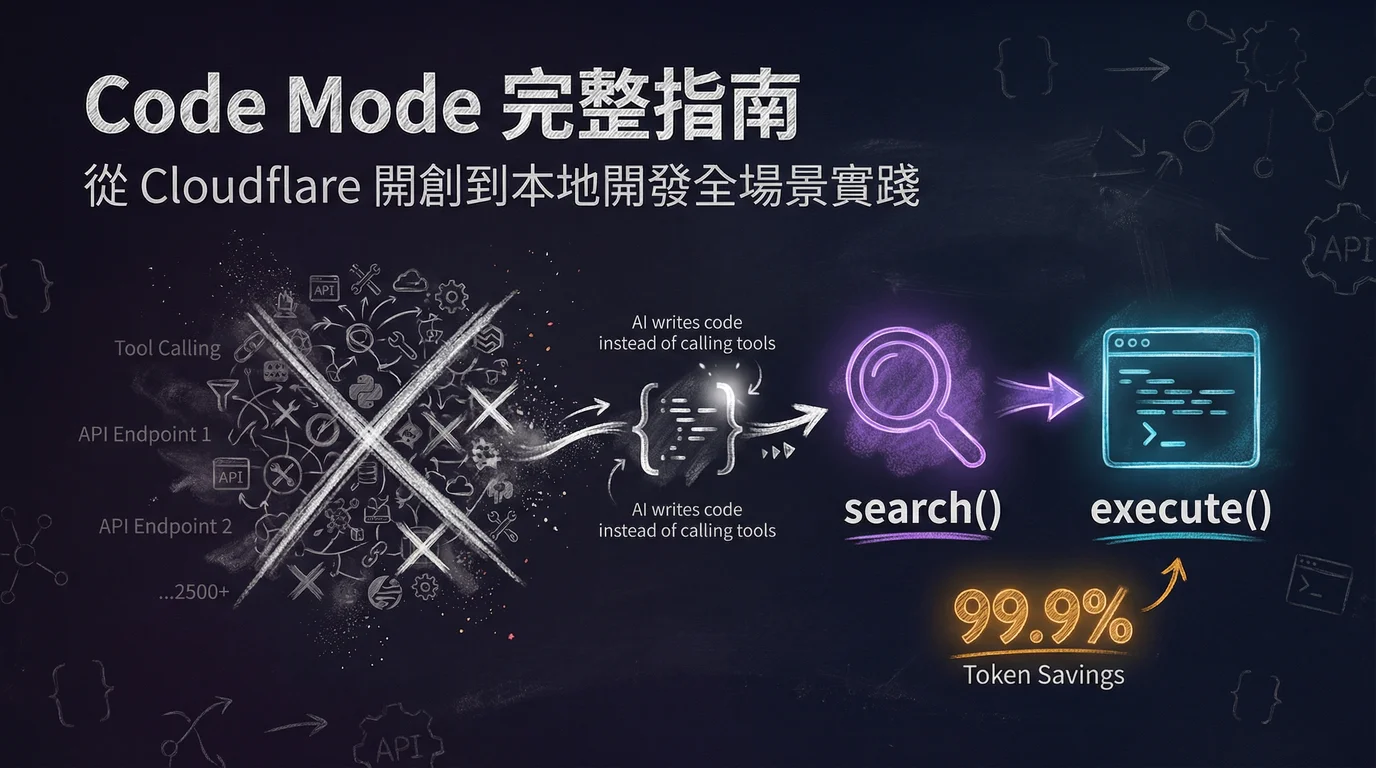
2025 年 9 月,Cloudflare 在官方部落格發了一篇文章:「Code Mode: give agents an entire API in 1,000 tokens」。文章點出一個關鍵問題——當 AI Agent 要操作擁有數千個 API 端點的大型服務時,傳統的工具呼叫(Tool Calling)方式已經撐不住了。
問題的本質:
MCP(Model Context Protocol)是 Anthropic 主導的開放標準,讓 AI Agent 安全連接外部工具與 API。傳統 MCP 把每個 API 端點當成獨立「工具」來描述——名稱、參數格式、回傳型別,一個不少。端點少的時候沒問題。但 Cloudflare 有 2,500 個以上端點,光是把工具描述塞進上下文,就要超過 117 萬個 Token。
AI 還沒開始做事,上下文視窗就已經被塞爆了。
Code Mode 的解答:
Cloudflare 的解法很簡潔——與其讓 AI 記住所有 API 的細節,不如把 AI 變成一個「會自己查文件、寫腳本的工程師」。這個新做法被稱為 Code Mode(程式碼模式),算是 AI Agent 領域的一次 典範轉移(Paradigm Shift)。
核心思想很簡單:
不要給 AI 兩千五百個按鈕,給它一本說明書和一台電腦。
1.2 兩個核心工具:search() 與 execute() 的設計哲學
Code Mode 將整個龐大的 API 介面收斂成僅僅兩個工具:
search(code) — AI 的「文件查詢員」
- AI 寫一段 JavaScript,在伺服器端的 OpenAPI spec 上搜尋、過濾端點。
- 例如:AI 想找跟防火牆相關的 API,它會寫類似以下邏輯的程式碼:
// AI 生成的 search 程式碼
const results = endpoints.filter(ep =>
ep.path.includes('firewall') || ep.description.includes('WAF')
);
return results.map(ep => ({
method: ep.method,
path: ep.path,
summary: ep.summary
}));
- 伺服器只回傳符合條件的端點摘要,而不是全部 2,500 個端點的完整描述。
execute(code) — AI 的「程式碼執行器」
- AI 寫一段完整的 JavaScript,實際呼叫 API、處理回應,甚至串接多個操作。
- 程式碼在伺服器端的 V8 隔離沙箱中執行,只把最終結果回傳。
// AI 生成的 execute 程式碼
const zones = await api.get('/zones');
const myZone = zones.find(z => z.name === 'example.com');
const rules = await api.get(`/zones/${myZone.id}/firewall/rules`);
return {
zone: myZone.name,
activeRules: rules.filter(r => r.enabled).length,
totalRules: rules.length
};
兩種模式的關鍵差異:
| 面向 | 傳統 Tool Calling | Code Mode |
|---|
| AI 的角色 | 按鈕操作員(選擇工具 → 填參數) | 程式設計師(理解需求 → 寫腳本) |
| 探索方式 | 被動接收完整工具清單 | 主動搜尋需要的端點 |
| 執行方式 | 每個操作一次 JSON 呼叫 | 單一腳本完成所有操作 |
| 上下文消耗 | 隨端點數量線性成長 | 恆定約 1,000 tokens |
| 錯誤處理 | 每步都可能中斷,需重新開始 | 腳本內建 try-catch,一次搞定 |
1.3 99.9% token 節省的關鍵數字(1.17M → 1069 tokens)
Cloudflare 在官方部落格中給出了實測數字:
| 指標 | 傳統 MCP | Code Mode | 節省幅度 |
|---|
| 工具描述 token 數 | 1,170,000 | 1,069 | 99.91% |
| 工具數量 | 2,500+ | 2 | 99.92% |
| 完成任務所需來回次數 | 數十次 | 2-4 次 | ~90% |
| 單次操作的上下文負擔 | 數十萬 tokens | 數百 tokens | ~99% |
這不是理論推算。Cloudflare 用自家完整 API(DNS、CDN、WAF、Workers、R2 等)實測出來的。
為什麼節省這麼多?
- 工具描述非常精簡: 傳統方式得描述每個端點的名稱、路徑、HTTP 方法、所有參數和回傳格式。Code Mode 只需兩個工具——「接受程式碼字串,回傳結果」。就這樣。
- 按需載入: AI 不需要一次看完所有 API,用到什麼查什麼。
- 結果精煉: 程式碼在沙箱內過濾掉無用資訊,只回傳 AI 真正需要的精華。
1.4 Anthropic 官方的認可與採用
這不只是 Cloudflare 一家的事。MCP 的發明者 Anthropic 後來也發表了「Code execution with MCP」,正式認可這個模式。
Anthropic 的研究結論與 Cloudflare 不謀而合:
LLM 撰寫程式碼來呼叫工具的效率,遠高於逐一使用結構化工具呼叫。
Code Mode 已經從一家公司的實驗,變成 業界共識。未來 MCP 伺服器會更傾向提供 execute_code,而非數百個獨立工具。
持續演進: 2026 年 2 月 20 日,Cloudflare 釋出 @cloudflare/codemode v0.1.0。這個 SDK 將 Code Mode 重寫為 runtime-agnostic 模組,其他平台能直接採用。社群端也有 portofcontext/pctx 等開源框架接連出現,生態版圖正快速擴張。
二、技術原理:如何解決 HTML 塞爆問題
2.1 傳統爬蟲的老問題(2MB HTML 問題)
用一個具體場景來說明:你請 AI 幫你爬取一個網頁的標題和主要內容。
傳統流程:
- AI 呼叫
fetch_url("https://example.com") 工具 - 工具回傳整個頁面的 HTML 原始碼
- AI 收到的是一坨混雜著
<div>、<script>、<style>、<nav> 的 2MB 原始碼 - AI 得用自己的 Token(你付費的算力)去「讀」這 2MB 垃圾
- Token 瞬間爆表,AI 不是超出上下文限制就是品質嚴重下降
真實數字感受:
| 頁面類型 | HTML 大小 | 估計 Token 數 | 以 Claude Sonnet 計費 |
|---|
| 簡單部落格 | 100KB | ~25,000 | ~$0.075 |
| 新聞網站首頁 | 500KB | ~125,000 | ~$0.375 |
| 電商產品頁 | 2MB | ~500,000 | ~$1.50 |
| SPA 應用(渲染後) | 5MB+ | ~1,250,000 | ~$3.75 |
而你真正需要的「標題和主要內容」可能只有 200 個 Token。也就是說,99.98% 的 Token 被浪費在 HTML 標籤、CSS、JavaScript 和導覽列上。
2.2 傳統 MCP 的「上下文塞爆」困境
爬蟲問題只是冰山一角。在傳統 MCP 架構中,「上下文塞爆」是個嚴重的結構性問題:
場景一:大型 API 操作
想讓 AI 操作 Cloudflare?光是工具描述就吃掉 117 萬 Token。AI 還沒開始做事就「失憶」了——上下文全被工具描述塞滿,沒空間處理你的需求。
場景二:多步驟自動化
想讓 AI 「查 50 筆日誌 → 找出錯誤 → 分類統計」?傳統方式需要:
- 50 次
read_log 工具呼叫(每次都是完整的 JSON 往返) - 每次回傳都塞進上下文
- 累積到第 20 筆,AI 已經忘記第 1 筆的內容
- 最後 AI 產生幻覺或直接當機
場景三:批量檔案處理
想讓 AI 重構專案裡 100 個檔案?傳統方式需要:
- 100 次
read_file 呼叫 - 上下文裡裝了幾十萬行程式碼
- AI 很容易搞混檔案、漏改、或產生不一致的修改
根本問題: 傳統 MCP 讓 AI 拿自己昂貴的「大腦」(上下文視窗)去處理大量原始資料。好比叫頂級律師親自影印一千頁文件——效率極低,成本極高。
2.3 Code Mode 的沙盒解析機制(V8 Dynamic Worker)
Code Mode 的解法很漂亮:讓 AI 寫程式來處理苦工,AI 本身只接收整理好的結果。
架構圖:
flowchart TD
A["👤 使用者"] --> B["🤖 AI 模型"]
B -->|"search() / execute()"| C["📡 MCP Server"]
C --> D["🔒 V8 隔離沙箱<br/>Dynamic Worker"]
D --> E["AI 撰寫的程式碼"]
E --> E1["搜尋 OpenAPI spec"]
E --> E2["呼叫 API"]
E --> E3["解析回應"]
E --> E4["過濾無用資訊"]
E1 & E2 & E3 & E4 --> F["✨ 精煉結果<br/>(數百 Token)"]
F --> B
style D fill:#0f3460,stroke:#5dade2,stroke-width:2px
style F fill:#1a5c2a,stroke:#2ecc71,stroke-width:2px
V8 隔離沙箱的特性:
Cloudflare 用的是跟 Workers 相同的 V8 隔離環境(也叫 Dynamic Worker),安全特性如下:
| 特性 | 說明 |
|---|
| 記憶體隔離 | 每次執行都在獨立的 V8 Isolate 中,無法存取其他程序的記憶體 |
| 無檔案系統 | 沙箱內沒有檔案系統存取權限 |
| 網路受控 | 只能存取預先授權的 API 端點 |
| 環境變數隔離 | 不會洩漏伺服器的環境變數或密鑰 |
| 超時機制 | 程式碼執行有時間上限,防止無窮迴圈 |
| 閱後即焚 | 執行完畢後沙箱自動銷毀,不留痕跡 |
以爬蟲為例的完整流程:
- 使用者:「幫我爬 Hacker News 首頁前 30 篇文章的標題和連結」
- AI 生成程式碼:
import requests
from bs4 import BeautifulSoup
resp = requests.get("https://news.ycombinator.com")
soup = BeautifulSoup(resp.text, "html.parser")
items = soup.select(".titleline > a")[:30]
result = [{"title": a.text, "link": a["href"]} for a in items]
print(json.dumps(result, ensure_ascii=False, indent=2))
- 程式碼在沙盒執行:下載 HTML(500KB)→ 在沙箱內解析 → 提取 30 筆資料
- 回傳給 AI 的結果:一個乾淨的 JSON 陣列,約 200 Token
500KB 的 HTML 從未進入 AI 的上下文。 AI 只花了幾百 Token 寫腳本,幾百 Token 讀結果。
2.4 對比表:傳統 MCP vs Code Mode
| 比較項目 | 傳統 MCP | Code Mode MCP |
|---|
| 工具數量 | 數千個獨立工具(每個 API 端點一個) | 僅 2 個(search + execute),或 1 個(execute_code) |
| 工具描述的 Token 消耗 | 隨端點數量線性成長(百萬級) | 固定 ~1,000 tokens,與 API 大小無關 |
| AI 的角色 | 工具操作員(選擇工具 → 填入參數) | 程式設計師(理解需求 → 撰寫腳本) |
| 探索 API 的方式 | 被動:接收完整工具列表 | 主動:撰寫程式碼搜尋 OpenAPI spec |
| 執行方式 | 每個操作一次 JSON 格式的工具呼叫 | 單一腳本完成所有操作(含迴圈、條件判斷) |
| 鏈式操作能力 | 需要多輪對話,每輪一個操作 | 一段程式碼內完成多步驟串接 |
| 資料過濾 | AI 用自己的 Token 閱讀全部回傳資料 | 程式碼在沙箱內過濾,只回傳精華 |
| 安全性 | 視伺服器實作而定 | 強制隔離(V8 / Docker / Podman) |
| 錯誤處理 | 每步可能中斷,需重新開始 | 腳本內建 try-catch,自行處理異常 |
| 適用的 API 規模 | 小型(<100 端點)表現尚可 | 任何規模都適用,API 越大優勢越明顯 |
三、在 Claude Code 使用 Code Mode
3.1 官方 MCP 掛載(Cloudflare):完整步驟含 OAuth 設定
Claude Code 原生支援 MCP,掛載只需一行指令。
步驟一:新增 Cloudflare MCP
claude mcp add --transport http cloudflare https://mcp.cloudflare.com/mcp
步驟二:完成 OAuth 認證
在 Claude Code 的交互介面中輸入:
/mcp
這會開啟 Cloudflare OAuth 2.1 認證流程。瀏覽器完成登入授權後,Claude Code 就能以你的身份操作 Cloudflare API。
步驟三:直接使用自然語言下達指令
幫我查看 example.com 目前的 DNS 記錄
AI 會自動:
- 呼叫
search() 找到 DNS 相關的 API 端點 - 呼叫
execute() 撰寫腳本列出所有 DNS 記錄 - 回傳整理好的結果
進階設定(可選):限制可操作的 zone
OAuth 預設授權帳號下所有 zone。若要限縮範圍,改用 API Token 認證:
- 到 Cloudflare Dashboard → API Tokens,建立權限受限的 Token(指定 zone 與權限)
- 將 Token 填入 MCP 設定:
{
"mcpServers": {
"cloudflare": {
"url": "https://mcp.cloudflare.com/mcp",
"transport": "http",
"headers": {
"Authorization": "Bearer YOUR_SCOPED_TOKEN"
}
}
}
}
注意: Zone 存取範圍由 Cloudflare 端的 Token 權限決定,不是 MCP JSON 裡的設定。
3.2 社群 MCP 掛載(Replicate, jx-codes, elusznik):各自安裝指令
Replicate Code Mode MCP
讓 AI 用程式碼方式操作 Replicate 的模型(生圖、生影片等):
claude mcp add "replicate-code-mode" -- npx -y replicate-mcp@alpha --tools=code
裝好後,AI 生成圖片或影片時會自己寫程式碼呼叫 SDK,不再逐一填工具參數。
jx-codes/codemode-mcp(JS/Deno 輕量代理)⚠️ 已停止維護
注意: 此專案已停止維護,作者轉向開發 jx-codes/lootbox。以下指令仍可用,但不會再更新。若需積極維護的多 MCP 整合方案,建議改用 pctx(見下方)。
適合想把多個傳統 MCP 伺服器整合成 Code Mode 的進階使用者:
# 安裝
npm install -g @jx-codes/codemode-mcp
# 在 Claude Code 中掛載
claude mcp add "codemode-proxy" -- npx @jx-codes/codemode-mcp --config ./codemode.json
設定檔範例 codemode.json:
{
"upstreamServers": [
{
"name": "filesystem",
"command": "npx",
"args": ["@modelcontextprotocol/server-filesystem", "/path/to/project"]
},
{
"name": "github",
"command": "npx",
"args": ["@modelcontextprotocol/server-github"]
}
],
"sandbox": {
"timeout": 30000,
"allowNetwork": false
}
}
portofcontext/pctx(開源 model-agnostic Code Mode 框架)🆕
2025 年 11 月出現的開源專案,不綁特定模型。The New Stack 曾專文報導。核心以 Rust 寫成,內建 Deno 沙盒執行環境(10 秒超時、禁止存取檔案系統、網路僅限設定的 MCP 主機),並搭載 TypeScript 編譯器(採 typescript-go,型別檢查 < 100ms)。支援 Claude、GPT、Gemini 及任何本地模型,無 vendor lock-in。
pctx 提供三個 MCP 工具:
| 工具 | 功能 |
|---|
list_functions() | 列出所有可用函式的 TypeScript namespace |
get<em>function</em>details(functions) | 取得函式完整的 TypeScript 簽章與 JSDoc 文件 |
execute(code) | 在 Deno 沙盒中執行 TypeScript,回傳 { success, stdout, output, diagnostics } |
macOS 安裝步驟(brew 環境):
# 1. 安裝 pctx CLI
brew install portofcontext/tap/pctx
# 2. 初始化設定檔(在專案目錄執行)
pctx mcp init
# 3. 加入你想整合的 upstream MCP server
# HTTP MCP server(如 Stripe、Cloudflare)
pctx mcp add stripe https://mcp.stripe.com --bearer "${STRIPE_MCP_KEY}"
# stdio MCP server(如 memory、filesystem)
pctx mcp add memory --command "npx -y @modelcontextprotocol/server-memory"
# 4. 測試連線
pctx mcp list
其他安裝方式:
# npm 全域安裝
npm i -g @portofcontext/pctx
# cURL 一鍵安裝
curl --proto '=https' --tlsv1.2 -LsSf https://raw.githubusercontent.com/portofcontext/pctx/main/install.sh | sh
# 更新
brew upgrade pctx # brew
npm upgrade -g @portofcontext/pctx # npm
pctx-update # cURL 安裝的用這個
在 Claude Code 中設定:
claude mcp add 有三種作用域(scope):
| Scope | 寫入檔案 | 作用範圍 |
|---|
--scope user | ~/.claude.json | 全域,所有專案都能用 |
--scope local(預設) | ~/.claude.json | 僅限當前專案(個人私有,不進 git) |
--scope project | .mcp.json(專案根目錄) | 專案層級,會進 git,可與團隊共用 |
方法一:CLI 指令(全域,推薦個人用)
# 新增(全域,所有專案都能用)
claude mcp add pctx --scope user -- pctx mcp start --stdio
# 更新:先刪再加
claude mcp remove pctx && claude mcp add pctx --scope user -- pctx mcp start --stdio
# 查看設定
claude mcp get pctx
claude mcp list
方法二:.mcp.json(--scope project,適合團隊共用)
在專案根目錄放 .mcp.json,commit 進 git,全隊共用:
{
"mcpServers": {
"pctx": {
"type": "stdio",
"command": "pctx",
"args": ["mcp", "start", "--stdio"]
}
}
}
注意: --stdio 模式需要工作目錄下有 pctx.json。先跑 pctx mcp init 建立,否則啟動會失敗。pctx.json 在別的路徑,用 --config 指定:
"args": ["mcp", "start", "--stdio", "--config", "/path/to/pctx.json"]
在 Cursor 中設定(~/.cursor/mcp.json):
{
"mcpServers": {
"pctx": {
"command": "pctx",
"args": ["mcp", "start", "--stdio"]
}
}
}
pctx.json 設定檔範例:
{
"name": "my-ai-agent",
"version": "1.0.0",
"servers": [
{
"name": "stripe",
"url": "https://mcp.stripe.com",
"auth": {
"type": "bearer",
"token": "${env:STRIPE_MCP_KEY}"
}
},
{
"name": "gdrive",
"url": "https://mcp.gdrive.example.com",
"auth": {
"type": "headers",
"headers": { "x-api-key": "${keychain:gdrive-api-key}" }
}
},
{
"name": "memory",
"command": "npx -y @modelcontextprotocol/server-memory"
}
]
}
pctx 支援三種安全取得密鑰的方式:
| 語法 | 來源 | 範例 |
|---|
${env:NAME} | 環境變數 | ${env:STRIPE<em>MCP</em>KEY} |
${keychain:NAME} | macOS Keychain | ${keychain:mcp-api-key} |
${command:CMD} | 外部指令 stdout | ${command:op read op://vault/item/field} |
# 將密鑰存入 macOS Keychain
security add-generic-password -s pctx -a my-key -w "your-secret-value"
Python SDK 安裝與使用:
pctx 除了 CLI(作為 MCP server 給 Claude Code / Cursor 用),也提供 Python SDK,讓你用 Python 寫 agent 直接呼叫 Code Mode。
# 基本安裝(需 Python >= 3.10)
pip install pctx-client
# 或用 uv
uv add pctx-client
# 搭配 AI 框架(按需選裝)
pip install "pctx-client[langchain]" # LangChain
pip install "pctx-client[openai]" # OpenAI Agents SDK
pip install "pctx-client[crewai]" # CrewAI
pip install "pctx-client[pydantic-ai]" # Pydantic AI
運作方式:先用 pctx start 啟動 HTTP 伺服器,再從 Python 連接:
# 終端 1:啟動 pctx HTTP 伺服器(預設 port 8080)
pctx start
# 終端 2:執行 Python agent
python main.py
from pctx_client import Pctx, tool
# 定義自訂工具
@tool
def get_weather(city: str) -> str:
"""Get weather information for a given city."""
return f"Sunny in {city}!"
# 連接 pctx 伺服器
p = Pctx(tools=[get_weather])
await p.connect()
# 取得各框架可用的工具
langchain_tools = p.langchain_tools() # LangChain
openai_tools = p.openai_agents_tools() # OpenAI Agents SDK
crewai_tools = p.crewai_tools() # CrewAI
兩種模式的差別:
pctx mcp start --stdio:作為 MCP server,給 Claude Code / Cursor 用pctx start:作為 HTTP 伺服器,給 Python SDK 用(預設 port 8080)
適用場景: 需要整合多個 MCP server 的複雜工作流。單一工具呼叫的簡單場景不適合,pctx 反而增加額外開銷。
elusznik/mcp-server-code-execution-mode(Python 容器沙箱)
本地開發最推薦的 Code Mode 伺服器。以 rootless 容器(Podman / Docker)執行 Python 程式碼,只暴露一個 run_python 工具,安全性最高(記憶體/CPU/PID 限制、capability drop、超時機制)。
注意: 此專案尚未發佈到 PyPI,uv tool install 和 pip install 都會失敗。請用下方 uvx --from git+ 安裝。
macOS 安裝步驟(brew + uv 環境):
# 1. 安裝容器執行環境(二選一,推薦 podman 更輕量無 daemon)
brew install podman
podman machine init && podman machine start
# 或 brew install --cask docker
# 2. 拉取 Python 基礎映像(只需一次)
podman pull python:3.13-slim
# 或 docker pull python:3.13-slim
# 3. 直接啟動 MCP 伺服器(無需 clone)
uvx --from git+https://github.com/elusznik/mcp-server-code-execution-mode mcp-server-code-execution-mode run
在 Claude Code 中永久設定(推薦):
方法一:CLI 指令(全域,寫入 ~/.claude.json)
# 新增(全域,所有專案都能用)
claude mcp add code-execution --scope user -e MCP_BRIDGE_RUNTIME=podman -- \
uvx --from git+https://github.com/elusznik/mcp-server-code-execution-mode \
mcp-server-code-execution-mode run
# 更新:先刪再加
claude mcp remove code-execution && claude mcp add code-execution ...
方法二:編輯 .mcp.json(專案層級,--scope project)
{
"mcpServers": {
"code-execution": {
"command": "uvx",
"args": [
"--from",
"git+https://github.com/elusznik/mcp-server-code-execution-mode",
"mcp-server-code-execution-mode",
"run"
],
"env": {
"MCP_BRIDGE_RUNTIME": "podman"
}
}
}
}
本地開發方式(如需修改原始碼):
git clone https://github.com/elusznik/mcp-server-code-execution-mode.git
cd mcp-server-code-execution-mode
uv sync
uv run python mcp_server_code_execution_mode.py
常見 macOS 問題:
| 問題 | 解法 |
|---|
| Podman 權限錯誤 | 執行 podman machine init 並啟動 |
| Docker Desktop 檔案共享 | Settings → Resources → File Sharing 加入 ~/MCPs |
uvx 找不到 | 確認 uv 在 PATH 中,重開終端或 source ~/.zshrc |
| 容器拉不到映像 | 手動執行 podman pull python:3.13-slim |
3.3 如何改變 Prompt 詠唱方式(對比傳統 vs Code Mode 提示詞)
Code Mode 不需要改變太多提示詞習慣,AI 會自動用 search 和 execute。但你可以稍微調整提示方式,引導 AI 更高效:
傳統提示詞:
幫我查一下 Cloudflare 的設定,然後幫我修改 WAF 規則。
Code Mode 優化提示詞:
你可以使用 search() 和 execute() 工具。
請先搜尋 Cloudflare 的 WAF 相關端點,
然後撰寫腳本列出我目前的 WAF 規則,
最後新增一條規則來阻擋來自高風險 IP 的請求。
對比表:
| 面向 | 傳統提示詞 | Code Mode 優化提示詞 |
|---|
| 指引程度 | 籠統(「幫我處理」) | 明確引導(「搜尋 → 腳本 → 執行」) |
| AI 效率 | 可能多次來回確認 | 一次到位 |
| 結果品質 | AI 可能漏掉步驟 | 步驟明確,不易遺漏 |
進階技巧:在 CLAUDE.md 或 System Prompt 中加入引導
如果你經常使用 Code Mode,可以在專案的 CLAUDE.md 中加入:
## Code Mode 使用指引
- 優先使用 search() 探索 API,不要猜測端點路徑
- 撰寫 execute() 腳本時,加入錯誤處理(try-catch)
- 批量操作時,先用腳本處理一小批測試,確認無誤再全量執行
- 回傳結果時只保留關鍵資訊,不要把完整 API 回應塞回上下文
四、在 Cursor 使用 Code Mode
4.1 MCP 設定方式(mcp.json 設定範例)
Cursor 也支援 MCP。在專案根目錄建 .cursor/mcp.json:
Cloudflare Code Mode:
{
"mcpServers": {
"cloudflare": {
"url": "https://mcp.cloudflare.com/mcp",
"transport": "http"
}
}
}
elusznik 本地 Code Mode:
{
"mcpServers": {
"code-exec": {
"command": "mcp-server-code-execution-mode",
"args": [],
"env": {
"CONTAINER_RUNTIME": "docker"
}
}
}
}
jx-codes 代理模式(串接多個 MCP): ⚠️ 已停維,見 lootbox
{
"mcpServers": {
"codemode-proxy": {
"command": "npx",
"args": ["@jx-codes/codemode-mcp", "--config", "./codemode.json"]
}
}
}
elusznik 本地 Code Mode(uvx 方式):
{
"mcpServers": {
"code-execution": {
"command": "uvx",
"args": [
"--from",
"git+https://github.com/elusznik/mcp-server-code-execution-mode",
"mcp-server-code-execution-mode",
"run"
],
"env": {
"MCP_BRIDGE_RUNTIME": "podman"
}
}
}
}
4.2 Cursor Rules 搭配技巧(.cursorrules 範例)
Cursor 支援 .cursorrules 指引 AI 行為。以下是 Code Mode 優化規則:
# Code Mode 使用規則
## 基本原則
- 當需要查詢 API 端點時,一律使用 search() 工具搜尋,不要猜測 API 路徑
- 當需要執行多步驟操作時,撰寫一段完整腳本使用 execute() 一次完成
- 避免把大量原始資料塞回上下文——在腳本內過濾和摘要
## 程式碼風格
- execute() 中的程式碼必須包含錯誤處理
- 使用 console.log() 或 print() 輸出結構化結果(JSON 格式優先)
- 批量操作前先用小量測試
## 安全原則
- 不要在程式碼中硬編碼任何密鑰或 Token
- 修改操作前先列出當前狀態(先查後改)
- 破壞性操作必須先確認
4.3 Human-in-the-loop 機制與安全確認
用 Code Mode 操作本地檔案或雲端服務時,安全確認機制很重要:
Claude Code 的安全機制:
Claude Code 內建權限系統。預設下,AI 執行 MCP 工具前會要求確認。你可以自行調整:
# 查看目前的權限設定
claude config list
# 允許特定 MCP 工具自動執行(進階使用者)
# 在 .claude/settings.json 中設定
Cursor 的安全機制:
Cursor 在 Agent 模式下會顯示 AI 即將執行的操作,你可以:
- 核准(Accept)
- 拒絕(Reject)
- 修改後核准
建議的安全策略:
| 操作類型 | 建議策略 |
|---|
| 唯讀操作(search、查詢) | 可設為自動執行 |
| 修改操作(更新設定、修改檔案) | 需人工確認 |
| 破壞性操作(刪除、重置) | 強制人工確認 + 先備份 |
| 網路操作(爬蟲、外部 API) | 需人工確認目標 URL |
五、八大場景教學
以下每個場景都包含:問題背景 → MCP 選擇理由 → 完整操作步驟 → 可執行程式碼範例 → 預期輸出格式
5.1 場景一:與大型 API 互動(Cloudflare 2500+ 端點)
問題背景:
你是一位網站管理者,使用 Cloudflare 管理多個網域。你想要:
- 查看所有網域的 DNS 記錄
- 為特定網域新增 WAF 規則
- 查看過去 24 小時的流量分析
傳統方式得翻 API 文件、找端點、搞懂參數格式,再逐一呼叫。用 Code Mode,AI 自己搞定。
MCP 選擇: cloudflare/mcp(官方,V8 隔離,99.9% token 節省)
完整操作步驟:
# 步驟 1:掛載 Cloudflare MCP
claude mcp add --transport http cloudflare https://mcp.cloudflare.com/mcp
# 步驟 2:認證
# 在 Claude Code 中輸入 /mcp,完成 OAuth 流程
提示詞範例:
我想了解我所有 Cloudflare 網域的狀態。請:
1. 列出所有 zone 及其狀態
2. 針對 example.com,列出所有 DNS 記錄
3. 新增一條 WAF 規則:阻擋 User-Agent 包含 "BadBot" 的請求
AI 生成的 search 程式碼範例:
// 搜尋 zone 和 DNS 相關的 API 端點
const results = endpoints.filter(ep =>
ep.path.includes('/zones') &&
(ep.tags.includes('Zone') || ep.tags.includes('DNS'))
);
return results.slice(0, 10).map(ep => ({
method: ep.method,
path: ep.path,
summary: ep.summary
}));
AI 生成的 execute 程式碼範例:
// 1. 列出所有 zone
const zonesResp = await api.get('/zones');
const zones = zonesResp.result.map(z => ({
name: z.name,
status: z.status,
plan: z.plan.name
}));
// 2. 取得 example.com 的 DNS 記錄
const myZone = zonesResp.result.find(z => z.name === 'example.com');
const dnsResp = await api.get(`/zones/${myZone.id}/dns_records`);
const dns = dnsResp.result.map(r => ({
type: r.type,
name: r.name,
content: r.content,
ttl: r.ttl
}));
// 3. 新增 WAF 規則
const wafRule = await api.post(`/zones/${myZone.id}/firewall/rules`, {
body: JSON.stringify([{
filter: { expression: 'http.user_agent contains "BadBot"' },
action: "block",
description: "Block BadBot user agent"
}])
});
return { zones, dns, wafRuleCreated: wafRule.success };
預期輸出:
{
"zones": [
{ "name": "example.com", "status": "active", "plan": "Pro" },
{ "name": "example.org", "status": "active", "plan": "Free" }
],
"dns": [
{ "type": "A", "name": "example.com", "content": "93.184.216.34", "ttl": 300 },
{ "type": "CNAME", "name": "www.example.com", "content": "example.com", "ttl": 300 },
{ "type": "MX", "name": "example.com", "content": "mail.example.com", "ttl": 3600 }
],
"wafRuleCreated": true
}
5.2 場景二:全先規劃開發新專案(從零開始的架構設計)
問題背景:
你打算從零建立一個 Next.js 全端應用,需要:
- 專案骨架(資料夾結構、設定檔)
- 資料庫 schema(PostgreSQL)
- API 路由設計
- 基本的認證系統
過去得一步步告訴 AI:「先建資料夾、再寫設定檔、再寫 schema…」。用 Code Mode,一段腳本就能搞定所有初始化。
MCP 選擇: elusznik/mcp-server-code-execution-mode(本地執行,可存取檔案系統)
完整操作步驟:
# 步驟 1:安裝 MCP
uv tool install mcp-server-code-execution-mode
# 步驟 2:掛載到 Claude Code
claude mcp add "code-exec" -- mcp-server-code-execution-mode
# 步驟 3:建立空專案目錄
mkdir my-nextjs-app && cd my-nextjs-app
提示詞範例:
我要建立一個 Next.js 15 全端應用,功能包含:
- 使用者認證(email + password)
- PostgreSQL 資料庫(用 Drizzle ORM)
- API 路由(RESTful 風格)
請用 execute_code 寫一段腳本,一次完成以下工作:
1. 生成完整的資料夾結構
2. 寫入所有設定檔(tsconfig, next.config, drizzle.config)
3. 建立 DB schema 定義檔
4. 建立基本的認證 API 路由
5. 列出所有建立的檔案清單
AI 生成的程式碼範例:
import os
import json
PROJECT_ROOT = "/workspace/my-nextjs-app"
# 定義資料夾結構
dirs = [
"src/app/api/auth/login",
"src/app/api/auth/register",
"src/app/api/auth/logout",
"src/app/(dashboard)",
"src/components/ui",
"src/lib",
"src/db",
"public",
]
for d in dirs:
os.makedirs(os.path.join(PROJECT_ROOT, d), exist_ok=True)
# 寫入 package.json
package_json = {
"name": "my-nextjs-app",
"version": "0.1.0",
"private": True,
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"db:generate": "drizzle-kit generate",
"db:migrate": "drizzle-kit migrate"
},
"dependencies": {
"next": "^15.0.0",
"react": "^19.0.0",
"react-dom": "^19.0.0",
"drizzle-orm": "^0.35.0",
"postgres": "^3.4.0",
"bcrypt": "^5.1.0"
},
"devDependencies": {
"typescript": "^5.6.0",
"drizzle-kit": "^0.26.0",
"@types/node": "^22.0.0",
"@types/react": "^19.0.0"
}
}
with open(os.path.join(PROJECT_ROOT, "package.json"), "w") as f:
json.dump(package_json, f, indent=2)
# 寫入 DB schema
schema_content = '''import { pgTable, text, timestamp, uuid } from "drizzle-orm/pg-core";
export const users = pgTable("users", {
id: uuid("id").primaryKey().defaultRandom(),
email: text("email").notNull().unique(),
passwordHash: text("password_hash").notNull(),
createdAt: timestamp("created_at").defaultNow().notNull(),
updatedAt: timestamp("updated_at").defaultNow().notNull(),
});
export const sessions = pgTable("sessions", {
id: uuid("id").primaryKey().defaultRandom(),
userId: uuid("user_id").references(() => users.id).notNull(),
expiresAt: timestamp("expires_at").notNull(),
createdAt: timestamp("created_at").defaultNow().notNull(),
});
'''
with open(os.path.join(PROJECT_ROOT, "src/db/schema.ts"), "w") as f:
f.write(schema_content)
# 列出所有建立的檔案
created_files = []
for root, dirs_list, files in os.walk(PROJECT_ROOT):
for file in files:
rel_path = os.path.relpath(os.path.join(root, file), PROJECT_ROOT)
created_files.append(rel_path)
print(f"已建立 {len(created_files)} 個檔案:")
for f in sorted(created_files):
print(f" - {f}")
預期輸出:
已建立 8 個檔案:
- drizzle.config.ts
- next.config.ts
- package.json
- src/app/api/auth/login/route.ts
- src/app/api/auth/register/route.ts
- src/db/index.ts
- src/db/schema.ts
- tsconfig.json
5.3 場景三:本地大型專案重構(萬行程式碼批量修改)
問題背景:
你有一個包含 200 個 TypeScript 檔案的專案,需要:
- 把所有
moment.js 的用法換成 dayjs - 更新所有 import 語句
- 調整日期格式化的 API 差異
- 確保修改不破壞 TypeScript 編譯
傳統 AI 得逐一讀每個檔案、理解用法、提出修改——光讀檔就要幾十萬 Token。
MCP 選擇: elusznik/mcp-server-code-execution-mode(本地執行,直接存取檔案系統,支援 Python 腳本)
完整操作步驟:
# 步驟 1:確認 MCP 已掛載
claude mcp list # 應該看到 code-exec
# 步驟 2:在專案目錄中啟動 Claude Code
cd /path/to/your/project
claude
提示詞範例:
這個專案目前使用 moment.js,我想全部遷移到 dayjs。
請用 execute_code 寫一段 Python 腳本來完成:
1. 掃描所有 .ts 和 .tsx 檔案,找出使用 moment 的位置
2. 將 import moment from 'moment' 改成 import dayjs from 'dayjs'
3. 將 moment() 呼叫改成 dayjs()
4. 將 .format('YYYY-MM-DD') 等保持不變(dayjs 格式相同)
5. 將 .toISOString() 保持不變
6. 將 .diff() 的用法轉換為 dayjs 的 .diff()
7. 輸出修改了哪些檔案和各自的修改數量
AI 生成的程式碼範例:
import os
import re
from pathlib import Path
PROJECT_ROOT = "/workspace/project"
EXTENSIONS = {".ts", ".tsx"}
# 替換規則
replacements = [
# import 語句
(r"import\s+moment\s+from\s+['\"]moment['\"]", "import dayjs from 'dayjs'"),
(r"import\s+\*\s+as\s+moment\s+from\s+['\"]moment['\"]", "import dayjs from 'dayjs'"),
(r"const\s+moment\s*=\s*require\s*\(\s*['\"]moment['\"]\s*\)", "import dayjs from 'dayjs'"),
# 函數呼叫
(r"\bmoment\(\)", "dayjs()"),
(r"\bmoment\(([^)]+)\)", r"dayjs(\1)"),
# 型別
(r"\bmoment\.Moment\b", "dayjs.Dayjs"),
(r"\bMoment\b(?=\s*[;,\)\]\}>])", "Dayjs"),
]
results = []
for root, _, files in os.walk(PROJECT_ROOT):
# 跳過 node_modules
if "node_modules" in root:
continue
for fname in files:
fpath = Path(root) / fname
if fpath.suffix not in EXTENSIONS:
continue
with open(fpath, "r", encoding="utf-8") as f:
original = f.read()
modified = original
change_count = 0
for pattern, replacement in replacements:
new_content, count = re.subn(pattern, replacement, modified)
change_count += count
modified = new_content
if change_count > 0:
with open(fpath, "w", encoding="utf-8") as f:
f.write(modified)
rel_path = os.path.relpath(fpath, PROJECT_ROOT)
results.append({"file": rel_path, "changes": change_count})
print(f"\n===== 重構完成 =====")
print(f"共修改 {len(results)} 個檔案,{sum(r['changes'] for r in results)} 處變更\n")
for r in sorted(results, key=lambda x: -x["changes"]):
print(f" [{r['changes']:3d} 處] {r['file']}")
預期輸出:
===== 重構完成 =====
共修改 47 個檔案,182 處變更
[ 12 處] src/utils/date-helpers.ts
[ 8 處] src/components/DatePicker.tsx
[ 7 處] src/pages/dashboard/analytics.tsx
[ 6 處] src/services/scheduler.ts
[ 5 處] src/hooks/useTimer.ts
...
AI 的 Token 消耗: 寫腳本約 500 Token + 讀取結果約 300 Token = 約 800 Token 完成 47 個檔案的重構。傳統方式可能需要 50,000+ Token。
5.4 場景四:網頁爬取(靜態頁面 + JavaScript 渲染頁面)
問題背景:
你想從技術新聞網站批量抓標題、連結和摘要,做每日新聞摘要。目標:
- Hacker News(靜態 HTML)
- TechCrunch(需要 JavaScript 渲染的 SPA)
MCP 選擇: elusznik/mcp-server-code-execution-mode(開啟網路存取後可爬取外部網頁)
完整操作步驟:
# 步驟 1:確認 MCP 已掛載並允許網路
# 在 elusznik 的設定中啟用網路存取
claude mcp add "code-exec" -- mcp-server-code-execution-mode --allow-network
提示詞範例(靜態頁面):
請用 execute_code 爬取 Hacker News 首頁前 30 篇文章,
提取標題、連結和分數,以 JSON 格式回傳。
AI 生成的程式碼範例(靜態頁面):
import requests
from bs4 import BeautifulSoup
import json
resp = requests.get("https://news.ycombinator.com", timeout=10)
soup = BeautifulSoup(resp.text, "html.parser")
articles = []
rows = soup.select("tr.athing")
for row in rows[:30]:
title_el = row.select_one(".titleline > a")
score_row = row.find_next_sibling("tr")
score_el = score_row.select_one(".score") if score_row else None
if title_el:
articles.append({
"rank": len(articles) + 1,
"title": title_el.text.strip(),
"link": title_el.get("href", ""),
"score": int(score_el.text.split()[0]) if score_el else 0
})
print(json.dumps(articles[:10], ensure_ascii=False, indent=2))
print(f"\n... 共 {len(articles)} 篇文章")
預期輸出:
[
{
"rank": 1,
"title": "Show HN: I built a local-first spreadsheet engine in Rust",
"link": "https://github.com/example/spreadsheet-rs",
"score": 342
},
{
"rank": 2,
"title": "Why SQLite is the most deployed database",
"link": "https://sqlite.org/mostdeployed.html",
"score": 289
}
]
... 共 30 篇文章
提示詞範例(JavaScript 渲染頁面):
TechCrunch 是 SPA,需要 JavaScript 渲染。
請用 execute_code 搭配 playwright 來爬取 TechCrunch 首頁最新 10 篇文章。
AI 生成的程式碼範例(JS 渲染頁面):
import asyncio
from playwright.async_api import async_playwright
import json
async def scrape_techcrunch():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
await page.goto("https://techcrunch.com", wait_until="networkidle")
articles = await page.evaluate('''
() => {
const items = document.querySelectorAll("article.post-block");
return Array.from(items).slice(0, 10).map(item => ({
title: item.querySelector("h2")?.textContent?.trim() || "",
link: item.querySelector("h2 a")?.href || "",
excerpt: item.querySelector(".post-block__content")?.textContent?.trim() || "",
author: item.querySelector(".river-byline__authors")?.textContent?.trim() || "",
}));
}
''')
await browser.close()
return articles
articles = asyncio.run(scrape_techcrunch())
print(json.dumps(articles, ensure_ascii=False, indent=2))
Token 消耗對比:
| 方式 | Token 消耗 | 耗時 |
|---|
| 傳統 fetch + AI 解析 HTML | ~125,000 tokens | 較慢(AI 讀 HTML) |
| Code Mode 腳本 | ~600 tokens | 極快(沙箱處理 HTML) |
5.5 場景五:資料處理(1GB CSV 清洗與統計分析)
問題背景:
你有一份 1GB 的電商交易紀錄 CSV 檔,需要:
- 清洗資料(移除空值、修正格式)
- 依月份統計營業額
- 找出 Top 10 暢銷商品
- 輸出摘要報告
把 1GB 的 CSV 塞進 AI 的上下文?這完全不可能。
MCP 選擇: elusznik/mcp-server-code-execution-mode(本地執行,可直接讀取大檔案)
提示詞範例:
我有一份大型 CSV 檔 /data/transactions.csv(約 1GB),
欄位包含:date, product_id, product_name, quantity, unit_price, customer_id
請用 execute_code 撰寫 Python 腳本:
1. 讀取並清洗資料(移除空值行、修正日期格式)
2. 計算每月總營業額
3. 找出 Top 10 暢銷商品(依總銷售額排序)
4. 計算基本統計資訊(總訂單數、總營業額、平均客單價)
5. 以結構化 JSON 格式輸出摘要
AI 生成的程式碼範例:
import pandas as pd
import json
from datetime import datetime
# 分塊讀取大檔案(避免記憶體爆掉)
chunks = pd.read_csv(
"/data/transactions.csv",
chunksize=100_000,
parse_dates=["date"],
dtype={"product_id": str, "customer_id": str}
)
# 初始化聚合容器
monthly_revenue = {}
product_sales = {}
total_orders = 0
total_revenue = 0.0
valid_rows = 0
invalid_rows = 0
for chunk in chunks:
# 清洗:移除空值
before = len(chunk)
chunk = chunk.dropna(subset=["date", "product_id", "quantity", "unit_price"])
invalid_rows += before - len(chunk)
valid_rows += len(chunk)
# 計算每筆交易金額
chunk["amount"] = chunk["quantity"] * chunk["unit_price"]
# 月營業額
chunk["month"] = chunk["date"].dt.to_period("M").astype(str)
for month, group in chunk.groupby("month"):
monthly_revenue[month] = monthly_revenue.get(month, 0) + group["amount"].sum()
# 商品銷售額
for _, row in chunk[["product_id", "product_name", "amount"]].iterrows():
pid = row["product_id"]
if pid not in product_sales:
product_sales[pid] = {"name": row["product_name"], "total": 0}
product_sales[pid]["total"] += row["amount"]
total_orders += len(chunk)
total_revenue += chunk["amount"].sum()
# Top 10 暢銷商品
top10 = sorted(product_sales.items(), key=lambda x: -x[1]["total"])[:10]
# 組裝報告
report = {
"summary": {
"total_orders": total_orders,
"valid_rows": valid_rows,
"invalid_rows_removed": invalid_rows,
"total_revenue": round(total_revenue, 2),
"avg_order_value": round(total_revenue / total_orders, 2) if total_orders > 0 else 0,
},
"monthly_revenue": dict(sorted(monthly_revenue.items())),
"top10_products": [
{"rank": i + 1, "id": pid, "name": info["name"], "revenue": round(info["total"], 2)}
for i, (pid, info) in enumerate(top10)
]
}
print(json.dumps(report, ensure_ascii=False, indent=2))
預期輸出:
{
"summary": {
"total_orders": 8234567,
"valid_rows": 8201234,
"invalid_rows_removed": 33333,
"total_revenue": 456789012.34,
"avg_order_value": 55.68
},
"monthly_revenue": {
"2025-01": 35678901.23,
"2025-02": 38901234.56,
"2025-03": 42345678.90
},
"top10_products": [
{ "rank": 1, "id": "P001", "name": "無線藍牙耳機", "revenue": 12345678.90 },
{ "rank": 2, "id": "P042", "name": "機械鍵盤", "revenue": 9876543.21 }
]
}
重點: 1GB 的 CSV 從未進入 AI 的上下文。AI 只花了約 800 Token 寫腳本,收到約 500 Token 的摘要結果。
5.6 場景六:自動化工作流(排程 + 條件觸發)
問題背景:
你想建立一個自動化工作流:
- 每天早上 9 點檢查 GitHub 上的 open issues
- 如果有超過 7 天未回應的 issue,自動標記為
stale - 將結果摘要發送到 Slack
MCP 選擇: jx-codes/codemode-mcp(可串接 GitHub MCP + Slack MCP)⚠️ 已停維,可改用 pctx
完整操作步驟:
# 步驟 1:安裝 codemode-mcp(仍可使用,但不再更新)
npm install -g @jx-codes/codemode-mcp
# 步驟 2:設定 upstream 伺服器
# 建立 codemode.json(見下方)
# 步驟 3:掛載到 Claude Code
claude mcp add "codemode" -- npx @jx-codes/codemode-mcp --config ./codemode.json
提示詞範例:
請用 execute_code 撰寫一段腳本,完成以下工作流:
1. 用 GitHub API 查詢 yelban/my-project 的所有 open issues
2. 找出超過 7 天沒有新留言的 issues
3. 為這些 issue 加上 "stale" 標籤
4. 組裝一份摘要訊息
5. 將摘要發送到 Slack 的 #dev-alerts 頻道
AI 生成的程式碼範例:
import { Octokit } from "@octokit/rest";
const octokit = new Octokit({ auth: process.env.GITHUB_TOKEN });
const REPO_OWNER = "yelban";
const REPO_NAME = "my-project";
const STALE_DAYS = 7;
// 1. 查詢所有 open issues
const { data: issues } = await octokit.issues.listForRepo({
owner: REPO_OWNER,
repo: REPO_NAME,
state: "open",
per_page: 100,
});
// 2. 找出超過 7 天未回應的
const now = new Date();
const staleIssues = issues.filter(issue => {
const lastActivity = new Date(issue.updated_at);
const daysSince = (now.getTime() - lastActivity.getTime()) / (1000 * 60 * 60 * 24);
return daysSince > STALE_DAYS && !issue.labels.some(l => l.name === "stale");
});
// 3. 標記 stale
for (const issue of staleIssues) {
await octokit.issues.addLabels({
owner: REPO_OWNER,
repo: REPO_NAME,
issue_number: issue.number,
labels: ["stale"],
});
}
// 4. 組裝 Slack 訊息
const summary = {
text: `🔔 Stale Issues 報告`,
blocks: [
{
type: "section",
text: {
type: "mrkdwn",
text: `*共 ${staleIssues.length} 個 issue 被標記為 stale*\n\n` +
staleIssues.map(i =>
`• <${i.html_url}|#${i.number}> ${i.title} (${Math.floor((now.getTime() - new Date(i.updated_at).getTime()) / 86400000)} 天未更新)`
).join("\n")
}
}
]
};
// 5. 發送到 Slack
const slackResp = await fetch(process.env.SLACK_WEBHOOK_URL, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(summary),
});
console.log(JSON.stringify({
totalOpen: issues.length,
newlyStale: staleIssues.length,
slackSent: slackResp.ok,
}, null, 2));
預期輸出:
{
"totalOpen": 23,
"newlyStale": 5,
"slackSent": true
}
5.7 場景七:複雜跨服務自動化 Orchestration(GitHub + DB + Slack 串接)
問題背景:
你是團隊技術主管,每週需要一份開發進度報告,包含:
- 本週合併的 PR 列表(從 GitHub)
- 每個 PR 對應的 Jira ticket 狀態(從資料庫)
- 開發者的 code review 統計
- 將報告發送到 Slack 的 #weekly-report 頻道
傳統做法:AI 分別呼叫 GitHub API、查資料庫、再叫 Slack API,每步一次工具呼叫。中間可能出錯、遺漏,上下文也容易被中間結果塞爆。
MCP 選擇: jx-codes/codemode-mcp(中央代理,串接 GitHub + PostgreSQL + Slack)⚠️ 已停維,可改用 pctx
提示詞範例:
請用 execute_code 產生本週的開發進度報告:
1. 從 GitHub API 拉取 yelban/main-project 本週合併的 PR
2. 從 PostgreSQL 的 jira_tickets 表格比對每個 PR 對應的 ticket 狀態
3. 統計每位開發者的 PR 數量和 review 數量
4. 將報告格式化後發送到 Slack #weekly-report
AI 生成的程式碼範例:
import os
import json
import requests
from datetime import datetime, timedelta
import psycopg2
# === 1. GitHub:拉取本週合併的 PR ===
GITHUB_TOKEN = os.environ["GITHUB_TOKEN"]
headers = {"Authorization": f"token {GITHUB_TOKEN}"}
one_week_ago = (datetime.now() - timedelta(days=7)).isoformat()
url = "https://api.github.com/repos/yelban/main-project/pulls"
params = {"state": "closed", "sort": "updated", "direction": "desc", "per_page": 100}
resp = requests.get(url, headers=headers, params=params)
all_prs = resp.json()
# 只保留本週合併的
merged_prs = [
pr for pr in all_prs
if pr.get("merged_at") and pr["merged_at"] >= one_week_ago
]
# === 2. PostgreSQL:比對 Jira ticket 狀態 ===
conn = psycopg2.connect(os.environ["DATABASE_URL"])
cur = conn.cursor()
pr_tickets = []
for pr in merged_prs:
# 從 PR title 或 branch 提取 ticket ID(例如 PROJ-123)
import re
match = re.search(r"(PROJ-\d+)", pr["title"] + " " + (pr["head"]["ref"] or ""))
ticket_id = match.group(1) if match else None
ticket_status = None
if ticket_id:
cur.execute("SELECT status FROM jira_tickets WHERE ticket_id = %s", (ticket_id,))
row = cur.fetchone()
ticket_status = row[0] if row else "NOT_FOUND"
pr_tickets.append({
"pr_number": pr["number"],
"title": pr["title"],
"author": pr["user"]["login"],
"merged_at": pr["merged_at"],
"ticket_id": ticket_id,
"ticket_status": ticket_status,
})
cur.close()
conn.close()
# === 3. 統計每位開發者 ===
dev_stats = {}
for pr in pr_tickets:
author = pr["author"]
if author not in dev_stats:
dev_stats[author] = {"prs_merged": 0, "tickets": []}
dev_stats[author]["prs_merged"] += 1
if pr["ticket_id"]:
dev_stats[author]["tickets"].append(pr["ticket_id"])
# === 4. 組裝並發送 Slack 報告 ===
report_lines = [f"📊 *本週開發進度報告* ({one_week_ago[:10]} ~ {datetime.now().strftime('%Y-%m-%d')})\n"]
report_lines.append(f"*合併 PR 數量:{len(merged_prs)}*\n")
report_lines.append("*各開發者統計:*")
for dev, stats in sorted(dev_stats.items(), key=lambda x: -x[1]["prs_merged"]):
report_lines.append(f" • {dev}: {stats['prs_merged']} PRs, tickets: {', '.join(stats['tickets']) or 'N/A'}")
report_lines.append("\n*PR 詳細列表:*")
for pr in pr_tickets:
status_emoji = "✅" if pr["ticket_status"] == "Done" else "🔄" if pr["ticket_status"] else "❓"
report_lines.append(
f" {status_emoji} #{pr['pr_number']} {pr['title']} (@{pr['author']}) [{pr['ticket_id'] or 'no ticket'}]"
)
slack_payload = {
"channel": "#weekly-report",
"text": "\n".join(report_lines),
}
slack_resp = requests.post(
os.environ["SLACK_WEBHOOK_URL"],
json=slack_payload,
timeout=10,
)
print(json.dumps({
"prs_merged": len(merged_prs),
"developers": len(dev_stats),
"slack_sent": slack_resp.ok,
"report_preview": "\n".join(report_lines[:10]) + "\n..."
}, ensure_ascii=False, indent=2))
預期輸出:
{
"prs_merged": 12,
"developers": 4,
"slack_sent": true,
"report_preview": "📊 *本週開發進度報告* (2026-02-14 ~ 2026-02-21)\n\n*合併 PR 數量:12*\n\n*各開發者統計:*\n • alice: 5 PRs, tickets: PROJ-234, PROJ-238, PROJ-241\n • bob: 4 PRs, tickets: PROJ-235, PROJ-239\n • charlie: 2 PRs, tickets: PROJ-237\n • diana: 1 PRs, tickets: PROJ-240\n..."
}
Token 消耗: 寫腳本 ~800 Token + 結果 ~400 Token = 約 1,200 Token 完成跨三個系統的自動化。傳統方式可能需要 20+ 輪對話、消耗 30,000+ Token。
5.8 場景八:跨系統整合(API + 本地檔案 + 外部服務一次搞定)
問題背景:
你需要完成一個完整的部署前檢查流程:
- 讀取本地的
package.json 確認版本號 - 檢查 GitHub 是否有未合併的 PR
- 執行本地測試套件
- 如果全部通過,更新 Cloudflare 的 DNS 指向新的部署 IP
- 發送結果通知
MCP 選擇: elusznik/mcp-server-code-execution-mode(本地執行,可存取檔案系統 + 網路)
提示詞範例:
請用 execute_code 撰寫部署前檢查腳本:
1. 讀取本地 /project/package.json 的版本號
2. 呼叫 GitHub API 檢查 main branch 是否有 pending PR
3. 執行 npm test 並捕捉結果
4. 如果全部通過,用 Cloudflare API 更新 app.example.com 的 A 記錄指向 203.0.113.50
5. 輸出完整的檢查報告
AI 生成的程式碼範例:
import json
import subprocess
import os
import requests
report = {"checks": [], "passed": True, "version": None}
# === 1. 讀取 package.json ===
try:
with open("/project/package.json", "r") as f:
pkg = json.load(f)
report["version"] = pkg["version"]
report["checks"].append({"name": "版本號讀取", "status": "PASS", "detail": f"v{pkg['version']}"})
except Exception as e:
report["checks"].append({"name": "版本號讀取", "status": "FAIL", "detail": str(e)})
report["passed"] = False
# === 2. 檢查 GitHub pending PR ===
try:
gh_headers = {"Authorization": f"token {os.environ['GITHUB_TOKEN']}"}
resp = requests.get(
"https://api.github.com/repos/yelban/project/pulls",
headers=gh_headers,
params={"state": "open", "base": "main"},
)
open_prs = resp.json()
if len(open_prs) > 0:
pr_list = [f"#{pr['number']}: {pr['title']}" for pr in open_prs[:5]]
report["checks"].append({
"name": "Pending PR 檢查",
"status": "WARN",
"detail": f"{len(open_prs)} 個未合併 PR: {', '.join(pr_list)}"
})
else:
report["checks"].append({"name": "Pending PR 檢查", "status": "PASS", "detail": "無 pending PR"})
except Exception as e:
report["checks"].append({"name": "Pending PR 檢查", "status": "FAIL", "detail": str(e)})
# === 3. 執行測試 ===
try:
result = subprocess.run(
["npm", "test", "--", "--reporter=json"],
cwd="/project",
capture_output=True,
text=True,
timeout=300,
)
if result.returncode == 0:
report["checks"].append({"name": "測試套件", "status": "PASS", "detail": "所有測試通過"})
else:
report["checks"].append({"name": "測試套件", "status": "FAIL", "detail": result.stderr[:500]})
report["passed"] = False
except Exception as e:
report["checks"].append({"name": "測試套件", "status": "FAIL", "detail": str(e)})
report["passed"] = False
# === 4. 更新 Cloudflare DNS(僅在全部通過時) ===
if report["passed"]:
try:
cf_headers = {
"Authorization": f"Bearer {os.environ['CF_API_TOKEN']}",
"Content-Type": "application/json",
}
# 找到 zone
zones_resp = requests.get(
"https://api.cloudflare.com/client/v4/zones",
headers=cf_headers,
params={"name": "example.com"},
)
zone_id = zones_resp.json()["result"][0]["id"]
# 找到 DNS 記錄
dns_resp = requests.get(
f"https://api.cloudflare.com/client/v4/zones/{zone_id}/dns_records",
headers=cf_headers,
params={"name": "app.example.com", "type": "A"},
)
record_id = dns_resp.json()["result"][0]["id"]
# 更新
update_resp = requests.put(
f"https://api.cloudflare.com/client/v4/zones/{zone_id}/dns_records/{record_id}",
headers=cf_headers,
json={"type": "A", "name": "app.example.com", "content": "203.0.113.50", "ttl": 300},
)
report["checks"].append({
"name": "DNS 更新",
"status": "PASS" if update_resp.json()["success"] else "FAIL",
"detail": "app.example.com → 203.0.113.50"
})
except Exception as e:
report["checks"].append({"name": "DNS 更新", "status": "FAIL", "detail": str(e)})
else:
report["checks"].append({"name": "DNS 更新", "status": "SKIP", "detail": "前序檢查未通過,跳過"})
# === 5. 輸出報告 ===
print(json.dumps(report, ensure_ascii=False, indent=2))
預期輸出:
{
"checks": [
{ "name": "版本號讀取", "status": "PASS", "detail": "v2.3.1" },
{ "name": "Pending PR 檢查", "status": "PASS", "detail": "無 pending PR" },
{ "name": "測試套件", "status": "PASS", "detail": "所有測試通過" },
{ "name": "DNS 更新", "status": "PASS", "detail": "app.example.com → 203.0.113.50" }
],
"passed": true,
"version": "2.3.1"
}
六、推薦開源 Code Mode 伺服器選型指南
6.1 選型決策樹(依需求快速選擇)
flowchart TD
Q{"你想用 Code Mode<br/>做什麼?"}
Q -->|操作 Cloudflare| CF["cloudflare/mcp<br/>(官方,零設定)"]
Q -->|操作 Replicate 模型| RP["replicate/<br/>replicate-mcp-code-mode"]
Q -->|本地開發| LOCAL{"需要哪種語言?"}
Q -->|網頁爬蟲| CRAWL{"頁面類型?"}
Q -->|多 MCP 整合| MULTI{"偏好?"}
Q -->|自訂 MCP 轉 Code Mode| ZB["zbowling/mcpcodeserver<br/>⚠️ 不活躍"]
LOCAL -->|Python 生態系| EL["elusznik/<br/>mcp-server-code-execution-mode<br/>⭐ 推薦"]
LOCAL -->|JS / TS| OV["dmmulroy/overseer"]
MULTI -->|"開源 model-agnostic"| PCTX["portofcontext/pctx<br/>🆕 推薦"]
MULTI -->|"Legacy"| JX["jx-codes/codemode-mcp<br/>⚠️ 已停維"]
CRAWL -->|靜態頁面| EL2["elusznik(開啟網路)"]
CRAWL -->|JS 渲染頁面| EL3["elusznik + Playwright"]
style Q fill:#e94560,stroke:#fff,color:#fff
style LOCAL fill:#0f3460,stroke:#5dade2,color:#fff
style CRAWL fill:#0f3460,stroke:#5dade2,color:#fff
style MULTI fill:#0f3460,stroke:#5dade2,color:#fff
style EL fill:#1a5c2a,stroke:#2ecc71,color:#fff
style PCTX fill:#1a5c2a,stroke:#2ecc71,color:#fff
6.2 各伺服器詳細評比表(含安裝指令、適用場景、安全性、難度評分)
| 項目 | cloudflare/mcp | elusznik | pctx 🆕 | overseer 🆕 | codemode-mcp | zbowling | replicate |
|---|
| 狀態 | ✅ 活躍(3.4K⭐) | ⚠️ 緩慢維護(307⭐) | ✅ 活躍(201⭐) | ✅ 活躍(199⭐) | ❌ 已停維(107⭐) | ❌ 不活躍(12⭐) | ❌ 不活躍(3⭐) |
| 語言 | TypeScript | Python | Rust + Python SDK | TypeScript | JS/Deno | TypeScript | JS |
| 執行環境 | Cloudflare Workers (V8) | Docker/Podman 容器 | Deno 沙盒(10s 超時) | Node.js | Deno 沙箱 | Node.js | Node.js |
| 安全隔離 | V8 Isolate + OAuth 2.1 | Rootless 容器(Podman 推薦) | Deno 沙盒 + 網路限 MCP 主機 | — | 30s 超時 + 網路受限 | TS 轉譯隔離 | SDK 層級 |
| Token 節省 | 99.9% | ~99% | 高 | 高 | 90%+ | 60-90% | 高 |
| 可存取本地檔案 | 否 | 是(掛載 volume) | 視設定 | 是 | 受限 | 受限 | 否 |
| 允許網路 | 僅 Cloudflare API | 可設定 | 可設定 | 可設定 | 預設關閉 | 視設定 | 僅 Replicate API |
| 特色 | 官方,零設定 | 安全性最高,macOS 友善 | Model-agnostic,多 MCP 整合,Python SDK | Agent task management | Legacy,轉至 lootbox | MCP 轉換器 | Replicate 專用 |
| 安裝難度 | ⭐ 低 | ⭐⭐ 中 | ⭐⭐ 中 | ⭐ 低 | ⭐ 低 | ⭐ 低 | ⭐⭐ 中 |
安裝指令速查:
# cloudflare/mcp(官方)
claude mcp add --transport http cloudflare https://mcp.cloudflare.com/mcp
# elusznik/mcp-server-code-execution-mode(⚠️ 未上 PyPI,用 uvx)
# 前置:brew install podman && podman machine init && podman machine start
uvx --from git+https://github.com/elusznik/mcp-server-code-execution-mode mcp-server-code-execution-mode run
# portofcontext/pctx 🆕
brew install portofcontext/tap/pctx
pctx mcp init && pctx mcp add stripe https://mcp.stripe.com
claude mcp add pctx --scope user -- pctx mcp start --stdio
# Python SDK: pip install pctx-client
# jx-codes/codemode-mcp(⚠️ 已停維 → lootbox)
npm install -g @jx-codes/codemode-mcp
claude mcp add "codemode" -- npx @jx-codes/codemode-mcp --config ./codemode.json
# zbowling/mcpcodeserver
claude mcp add "codeserver" -- npx mcpcodeserver
# replicate/replicate-mcp-code-mode
claude mcp add "replicate-code-mode" -- npx -y replicate-mcp@alpha --tools=code
6.3 多 MCP 串接架構圖
單一 MCP 模式(最簡單):
flowchart TD
IDE["🖥️ Claude Code / Cursor"] --> MCP["📡 Code Mode MCP Server<br/>(cloudflare/mcp)"]
MCP --> API["☁️ 目標服務 API<br/>(Cloudflare)"]
style IDE fill:#16213e,stroke:#5dade2,color:#e0e0e0
style MCP fill:#0f3460,stroke:#5dade2,color:#e0e0e0
style API fill:#1a5c2a,stroke:#2ecc71,color:#e0e0e0
代理模式(整合多服務):
flowchart TD
IDE["🖥️ Claude Code / Cursor"] --> PROXY["🔀 Code Mode Proxy<br/>(pctx / codemode-mcp)"]
PROXY --> FS["📁 Upstream 1<br/>filesystem(本地檔案)"]
PROXY --> GH["🐙 Upstream 2<br/>GitHub(程式碼管理)"]
PROXY --> PG["🗄️ Upstream 3<br/>PostgreSQL(資料庫)"]
PROXY --> SL["💬 Upstream 4<br/>Slack(通知)"]
style IDE fill:#16213e,stroke:#5dade2,color:#e0e0e0
style PROXY fill:#e94560,stroke:#fff,color:#fff
AI 只看到一個 execute_code 工具,但透過代理能操作所有底層 MCP 伺服器。代理負責:
- 把程式碼路由到正確的 upstream
- 管理權限與安全隔離
- 聚合結果回傳
混合模式(本地 + 雲端):
flowchart TD
IDE["🖥️ Claude Code / Cursor"] --> CF["☁️ cloudflare/mcp<br/>(雲端 API,直連)"]
IDE --> EL["🔒 elusznik<br/>(本地沙箱)"]
EL --> FS["📁 本地檔案系統"]
EL --> GIT["🔀 本地 Git"]
EL --> TEST["🧪 本地測試套件"]
style IDE fill:#16213e,stroke:#5dade2,color:#e0e0e0
style CF fill:#1a5c2a,stroke:#2ecc71,color:#e0e0e0
style EL fill:#0f3460,stroke:#5dade2,color:#e0e0e0
可以同時掛多個 Code Mode MCP,AI 會依任務自行選用。
參考資料
| 來源 | 連結 |
|---|
| Cloudflare 官方部落格:Code Mode | https://blog.cloudflare.com/code-mode-mcp/ |
| Cloudflare MCP Server 原始碼 | https://github.com/cloudflare/mcp |
@cloudflare/codemode SDK 文件 | https://developers.cloudflare.com/agents/api-reference/codemode/ |
| Anthropic 工程部落格:Code execution with MCP | https://www.anthropic.com/engineering/code-execution-with-mcp |
| portofcontext/pctx(開源 Code Mode 框架)🆕 | https://github.com/portofcontext/pctx |
| dmmulroy/overseer(Agent task management)🆕 | https://github.com/dmmulroy/overseer |
| elusznik/mcp-server-code-execution-mode | https://github.com/elusznik/mcp-server-code-execution-mode |
| jx-codes/codemode-mcp(⚠️ 已停維 → lootbox) | https://github.com/jx-codes/codemode-mcp |
| jx-codes/lootbox(codemode-mcp 後繼) | https://github.com/jx-codes/lootbox |
| Claude Code MCP 文件 | https://code.claude.com/docs/en/mcp |
| Awesome MCP Servers 列表 | https://github.com/wong2/awesome-mcp-servers |
全文共 6 章:原理、4 個平台設定、8 大實戰場景、5 個開源伺服器選型。
 orz99
orz99